
データベースの中身ってどうなっているのか
特にデータベースにまちゃまちゃ興味あるというわけでもないけど、MySQLは実際に触ってみたことがあって、アプリを実装している段階では内部で何やってんのか全然わからなくて気になってはいたんだよね。触ってみたことがあるってどれくらいのレベルかというと、数万行くらいのコードの製品のAPI書いてて、その中でいろいろDBとちょっとやりとりしてた感じくらい。言語はNode.jsとか。特段に高度なことはしていないけども、内部がどうなってるのかきになるよね。全部Dockerで包んでたからなおのことわかりづらかった。
なので、この本をポチりました(Database Internals)。安定のオライリー氏。今回はじめて洋書のオレイリーを紙で買ったんだけど、すぐ届いたから今度からKindleやめて紙にすることにしたよ。
で、肝心の中身なんですが、実は以前にもこれぽい本はおレイリーで読んだことあって(?Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems:以下猪本)、これはキンドルで読んだんだけど。去年の夏とかに挑戦したんだが難しくて当時のわしには無理だった、英語とDB両面で。ただDBの簡単なイメージみたいなのはそのおかげでついていたから、はあはあそういう感じねとなりながら今回読めた。その当時猪本を読んだ背景としてはこれからバックエンドのAPI書いてもらおうと思ってるみたいに言われたからなんだけど、初心者が読む感じのものというよりかは手作業ばっかやってた人が全体像を掴むための本みたいな感じだった、記憶がある。
この本は二つに別れてて、パート1と2になってるんだけど、1は一つのDBまでの話で、2から分散システム(複数のDB、マシンの協調)の話になっている。
自分が実際に経験したのはシングルクラスタレベルのDBの動作で、複数マシン(クラスタ)組み合わせた複雑なDB設計みたいなことしたことないから、この本の後半の方はちょっと読むモチベーションが湧かない可能性が一見して分かってしまった。しかしそれが一見してわかるだけでも紙の価値はやはりでかい。ペラペラめくるの便利すぎる、パピルス万歳。
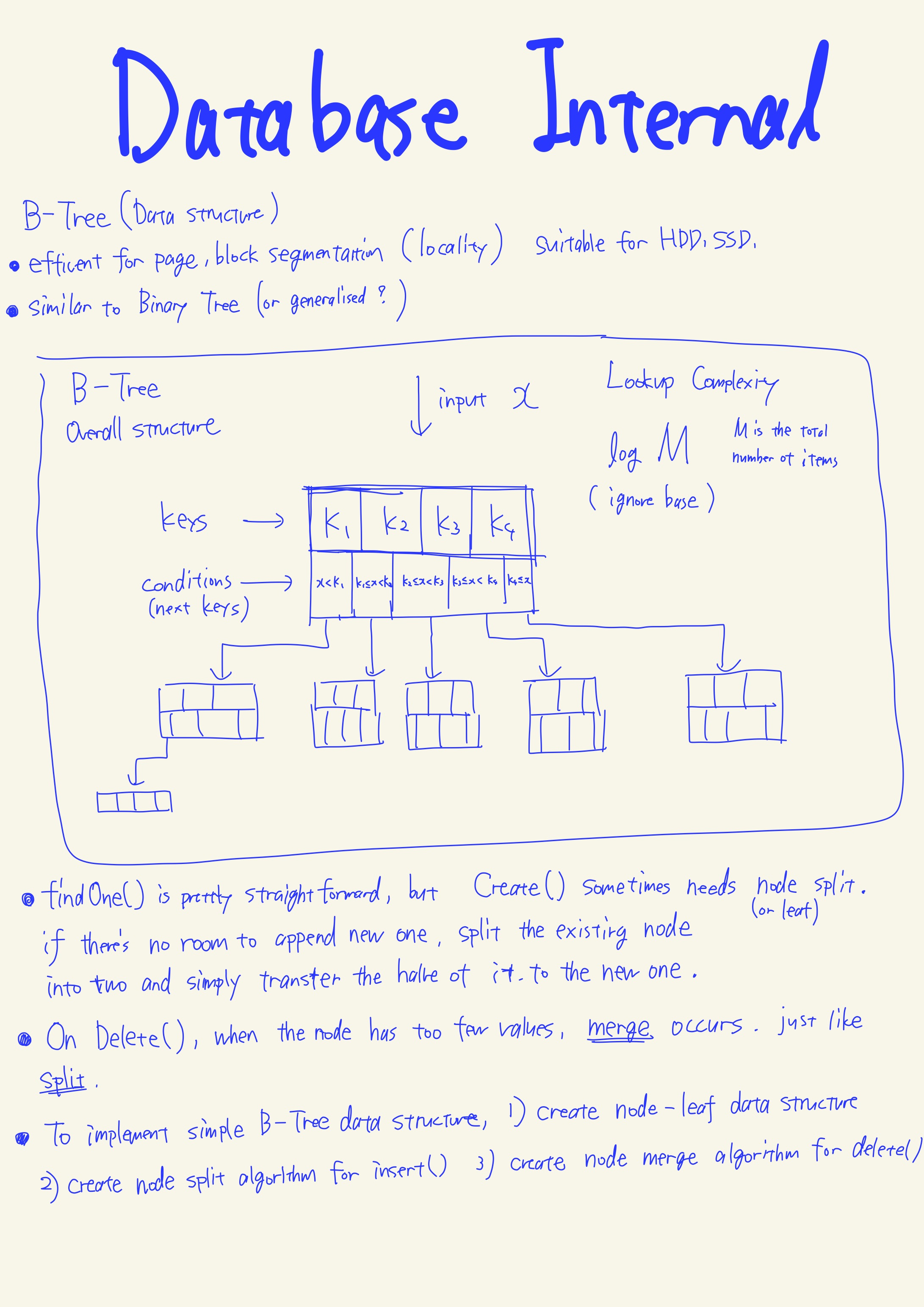
なのでまあ、前半だけでもちゃんと読もうと、iPadを開きつつ読んでました。B-Treeとかのmutableなデータ構造を基礎にして、ディスク上でデータを効率的にやり取りするためにfile formatをバイナリエンコードはもちろんとしてなんか工夫するんだね、一旦それでシンプルなデータ保存機構(insert, update, delete)とかは実現できるけど、やっぱりDBといったらトランザクションはらなきゃ、とか一部をメモリに乗せて高速化しなきゃ、とかメモリとディスクのシンクロちゃんとしなきゃ、とかデータ壊れたら復活させなきゃ、とか順序壊れない程度に性能上げるためにconcurrentに実行しなきゃとかそういう話があるから・・・みたいな。で、そいうところの概説っぽいのがありました。まあなんかこういうのもイノシシ本でうっすら触れていたから馴染みはあったな、結局。
そういうののコードベースでの実装例の紹介とかまではしていないぽい?でも概念はクリアに図もたっぷりに説明してくれてるから頑張れば実装できる感じする。
で、各種アルゴリズムの紹介とかB-Treeのvariantの紹介とかの部分は普通にモチベが続かなかった。immutableなLSM-Treeくらいまでは読む気が起こるかもしれない。というかぶっちゃけ英語でノートが学習の妨げにならないレベルで取れたことが一番のうれしみポイントだった(完)。
なんか書評みたいな感じになってるけど、文章量で言えば半分も読んでないです。ただB-Treeとtransaction, recovery, concurrency, page cacheあたりのところは正座して読んだ。



この本は手を動かせ!っていう感じのものでもない気がする。ただReferencesが異常に豊富で、220報とか引いてるからここをスタート地点に這い上がったらデーベーの専門家になれるやつだ。